Toetsen zijn aan de orde van de dag, in het onderwijs, in de media. Er valt op allerlei manieren van alles over te zeggen, maar de basis is toch wel hoe die toetsen zelf te beschrijven, als het kan in kwantitatieve dus wiskundige termen. Algebraïseren heet dat ook wel. Hoe zouden we dat kunnen aanpakken? Ik probeer het hier zo eenvoudig mogelijk uit te werken. Hoe algebraïseren we wat er gebeurt bij het toetsen van beheersing?
Er moet natuurlijk een wiskundig model zijn op te stellen, want we hebben er wel voor gezorgd dat de toets kwantiteiten oplevert, zoals ‘aantal goed’.
Het Nederlandse reken- en wiskundeonderwijs is vergeven van de opgaven in contexten. Welnu we hebben hier een mooie contextopgave wiskunde, laten we die eens aanpakken. Als u denkt dat ik ergens een rare sprong maak, laat het weten (reageer onder de blog). Een aantal eerste overwegingen, of aanwijzingen, puntsgewijs:
1) de beheersing van de stof moet in het model voorkomen, noem deze ‘p’.
2) een toets is geen meting, maar een steekproef; of eigenlijk: evenveel steekproeven als er bijvoorbeeld vragen in de toets zijn, noem dit aantal ‘n’.
Probeer niet meteen een formule op te stellen, maar beredeneer wat een acceptabel model zou kunnen zijn.
Een derde aanwijzing.
(3) De toets is een steekproef. Aha, veronderstel dat het een steekproef is uit een grote verzameling van vragen die geschikt zijn voor opname in een toets.
(4) De beheersing van de stof, ‘p’, definiëren we als de proportie vragen ‘goed’ als ALLE vragen uit die grote verzameling van vragen gemaakt zouden zijn.
(5) Ha ha, dat kan toch niet. Jawel, we kunnen het denken, als gedachtenexperiment.
Maar lopen we met (5) uiteindelijk niet ergens vast? Want ‘p’ kunnen we dan toch nooit weten? Dat klopt, maar we kunnen wel informatie over ‘p’ krijgen, door te toetsen hè! Dus hou vol, we komen er wel. Leraren wiskunde onder u moeten nu kunnen weten wat een passend model is.
Oké dan, een eerste model met die ‘n’ en ‘p’ voor toetsen is: voor iedere volgende vraag in de toets is de kans dat de leerling die goed kan maken gelijk aan ‘p’.
Breid het gedachtenexperiment verder uit: stel u voor dat die leerling heel veel van die steekproeftoetsen aflegt.
Zijn de scores op die toetsen dan allemaal gelijk? Bijvoorbeeld gelijk aan ‘p’ maal ‘n’? Nee, natuurlijk niet, het zijn allemaal nieuwe steekproeven. De scoreverdeling voor al die steekproeven kennen we wel uit de literatuur: de binomiaalverdeling. Kies bijvoorbeeld beheersing p = 0,6 en aantal toetsvragen n = 20, dan geeft WolframAlpha de scoreverdeling, klik: http://www.wolframalpha.com/input/?i=binomial+distribution+20+0.6 Tegenwoordig kan deze gratis app ook voor hogere waarden van n berekenen en plotten. Speel er mee, verander de waarde van de beheersing ‘p’, en het aantal vragen in de toets ‘n’. Denk eraan: dit is een gedachtenexperiment met ‘p’ en ‘n’.
Een andere app (er zijn er vast meer te vinden) die eenvoudiger is maar wel handige grafieken print: https://homepage.stat.uiowa.edu/~mbognar/applets/bin.html
Het gedachtenexperiment kan concreter: niet een zeer groot aantal toetsen gemaakt door dezelfde leerling met beheersing ‘p’, maar door een een zeer groot aantal leerlingen die, mirabele dictu, allemaal dezelfde beheersing ‘p’ hebben: Bi(80, 0.6), dezelfde plot als hierboven.
Deze plot van Bi(80, 0.6) geeft te denken. Hoe we het ook wenden of keren, alle deelnemers aan de toets hebben dezelfde beheersing van de stof, ‘p’, maar hun toetsscores hebben een verdraaid grote spreiding. En toch is dit een toets met een stevig aantal vragen: steekproef 80.
Had u dat verwacht? Dat de scores zo’n grote spreiding zouden laten zien, terwijl alle leerlingen DEZELFDE stofbeheersing ‘p’ hebben?
Eigenlijk had ik tevoren aan u moeten vragen: maak eens een schets van de afwijkingen van de verwachte score die, in dit geval, 48 is.
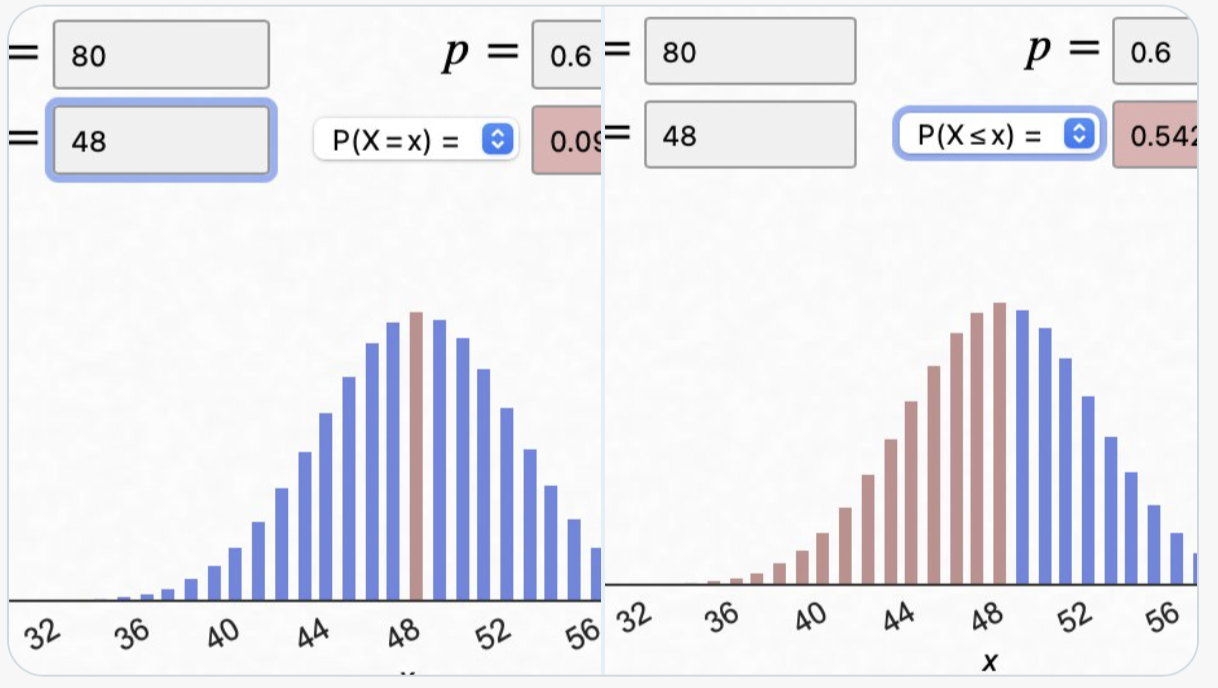
De app van Malt Bognar rekent ook uit wat bijvoorbeeld de kans is bij Bi(80, 0.6) dat de score op 48 uitkomt: 0,09 (figuur links); of dat de eindscore <= 48 is: (figuur rechts): 0,54 . Enzovoort.
We kunnen er dus aan (laten) rekenen.
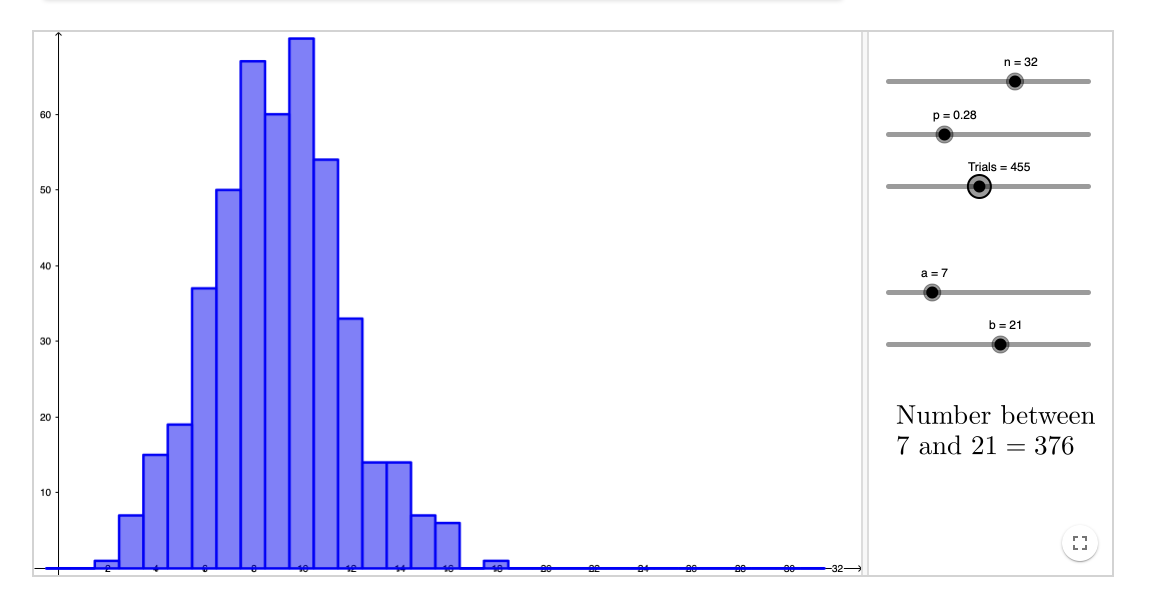
Maar simuleren kan ook. Daarvoor kunnen we terecht bij Geogebra https://www.geogebra.org/m/qkucpmmn (klik op de URL)
We hebben echt wel heel veel aan alleen al dit eenvoudige model. Een onverwacht voorbeeld is een bericht op 25 april 2024 https://www.volkskrant.nl/nieuws-achtergrond/praktijkonderwijs-en-vmbo-kampen-met-forse-daling-leerlingenaantallen-doorstroomtoets-lijkt-oorzaak~b250799c/ dat het vmbo substantieel minder leerlingen aangemeld heeft gekregen dan in het voorgaande jaar. Ik vermoed zomaar dat dit veel of alles heeft te maken met de nieuwe doorstroomtoets voor de overgang van po naar vo, met de nieuwe wetgeving die scholen verplicht om een evetueel hoger advies op basis van die toets over te nemen. De wetgever heeft zich niet gerealiseerd dat hiermee een aanzienlijke kwantitatieve verschuiving in de doorstroom naar het vo ontstaat. Aangenomen dat het advies van de school correspondeert met de relevante beheersing ‘p’, gaan bijna de helft van de leerlingen op een doorstroomtoets een HOGERE score krijgen, in de meeste gevallen zelfs zoveel hoger dat er ook een hoger ‘advies’ uitkomt. De doorstroomtoetsen werken dus als een loterij, met tientallen procenten ‘winnaars’ die in het vo op een jhoger niveau gaan instromen dan de school voor ogen had. Daar moet niemand blij mee zijn. Nou ja, het punt is hier: iedereen met enig inzicht in het steekproefkarakter van toetsen had dit probleem kunnen zien aankomen. Begrijpt u?
Terug naar: We kunnen er dus aan (laten) rekenen. Maar daar hebben we niet veel aan, want wat ‘p’ is dat kunnen we niet weten. Wat we wèl weten is dat bij een gegeven ‘p’=0,6 niet alle toetsscores even waarschijnlijk zijn.
Aha, daar kunnen we gebruik van maken.
Maar dan wel in omgekeerde zin: wat kunnen we weten over ‘p’ wanneer een leerling 48 goed scoort op een toets van 80 vragen? Immers, niet alle mogelijke waarden van ‘p’ zijn even waarschijnlijk.
Die verschillende waarschijnlijkheden zijn te berekenen, de plot is beta verdeeld.
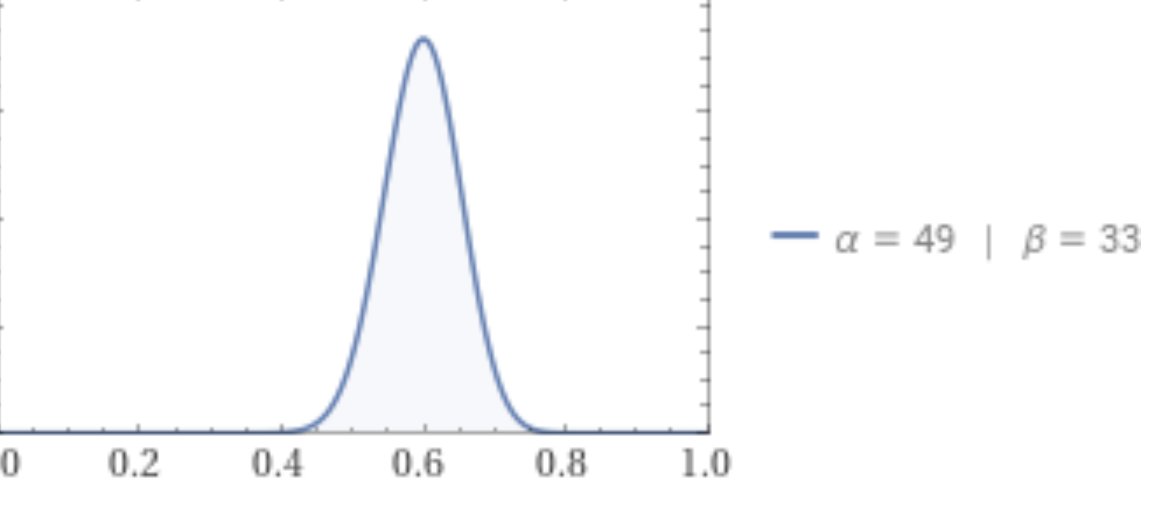
Deze plot (Woilfram) is geen kansverdeling, maar een aannemelijkheidsverdeling, of kortweg aannemelijkheid. De verticale schaal is bepaald door het maximum van de verdeling op 1 te stellen. Overigens is het een betadichtheid. Zie de app van WolframAlpha: https://www.wolframalpha.com/input?i=beta+distribution+49+33 beta distribution 49 33 – Wolfram|Alpha
Bij de score van 48 op de toets hoort de bovenstaande aannemelijkheid: in het gebied onder de curve ligt de ‘ware’ beheersing van de leerling met score 48.
Hoe weten we dat dit een betadichtheid is: uit de literatuur (bijvoorbeeld Novick & Jackson ‘Statistical methods’).
Maak u geen zorgen. De curve is te construeren door voor verschillende waarden van ‘p’ de binomiaalverdeling Bi(80, p) te genereren, en dan na te gaan wat de proportionele kans is op precies de score 48. Het is even een werkje, maar de computer doet het zonder sputteren.
De app van Wolfram kan voor de beta ook wat grotere waarden van de parameters a en b (alfa en beta) aan, speel er wat mee.
Hek ik al aangegeven wat die a en b voorstellen?
a = aantal goed + 1
b = aantal fout + 1
In het voorbeeld dus a = 48+1, b = 32+1, toets van n = 80 vragen.
Kunnen we de aannemelijkheid ook simuleren? Ja, . De app van Geogebra https://www.geogebra.org/m/qkucpmmn is hiervoor te gebruiken. (Geogebra is beperkt tot maximaal 50 vragen in de toets, jammer) Dat gaat als volgt, voor een toets van 40 vragen waarop een leerling 24 goed heeft gescoord: zet de waarde van ‘a’ op 24, de waarde van ‘b’ op 25. Schuif dan de waarde van ‘p’ op 0, en schuif langzaam naar ‘p’ = 1. Let op ‘Number between 24 and 25 = … . De aantallen nemen eerst toe, daarna af; de verdeling is ruw omdat we simuleren, maar er is prima een betaverdeling op te passen. Eigenlijk zouden we liefst proporties zien van scores die gelijk zijn aan 24, maar maar aantallen plotten komt op hetzelfde neer. De verdeling zelf wordt niet geplot, daar moet maatwerk-programmatuur voor worden gemaakt (SPA_likelihood).
Met de constructie van de aannemelijkheid hebben we het gedachtenexperiment verlaten: het gaat nu om statistische berekeningen uitgaande van een concreet waargenomen resultaat — 48 goed uit 80.
De plot geeft een precies beeld van welke waarden van ‘p’ hoe aannemelijk zijn.
Dat is fijn, maar is dat alles wat we eraan hebben? Nee.
Het aardige is nu dat deze aannemelijkheid het mogelijk maakt een kwantitatieve voorspelling te doen van de score die behaald kan worden op een onmiddellijke herkansing op bijvoorbeeld weer een toets van 80 vragen.
Door herhaaldelijk een willekeurig punt onder de aannemelijkheid te kiezen en voor de corresponderende waarde van ‘p’ de score op 80 vragen te berekenen of te simuleren.
De resulterende verdeling is de betabinomiaal https://www.wolframalpha.com/input?i=betabinomial+distribution+%5B49%2C+33%2C+80%5D
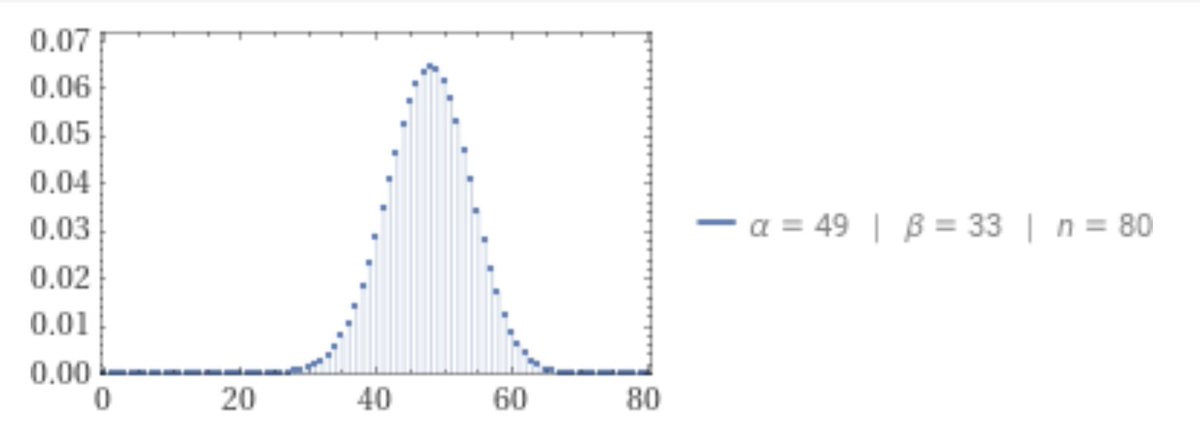
Geschrokken van de grote spreiding? !!!
Dat deze voorspellende verdeling een betabinomiaal is, weten we ook weer uit de theorie, en is overigens ook via simulatie te controleren. Die simulatie kan niet zomaar met bestaande programmatuur, want er moeten random waarden voor beheersing ‘p’ worden getrokken uit de oppervlakte onder de betaverdeling, voor iedere getrokken ‘p’ wordt een binomiaalscore gesimuleerd. Plot op basis van al die gesimuleerde scores de voorspellende toetsscoreverdeling. Hiervoor is maatwerk-programmatuur nodig. Dit is wat de SPA-applets zouden moeten doen, zie https://benwilbrink.nl/projecten/spa_predictor.htm .
SPA-project
Voor al het hierboven behandelde zie voor meer details het SPA-project https://benwilbrink.nl/projecten/spa_project.htm
Dat project is is helaas onaf, terwijl de JAVA-applets in dit project niet meer compatibel zijn met huidige JAVA-versies. (Mijn oude Macs draaien er nog wel goed op …. ).
Ooit ben ik in 1978 gestart met dit soort toets- en examenmodellen: https://benwilbrink.nl/publicaties/78StudiestrategieCOWO.htm
Wie de standaard-literatuur over toetsen een beetje kent, is nu misschien totaal in verwarring geraakt. Het bovenstaande is immers een totaal andere benadering dan in ‘mainstream’ psychometrische literatuur is te vinden.
Er valt dan ook nog veel meer over te zeggen, zie SPA.
Een dingetje dat ik hier nog wel moet aanstippen: in mijn uiteenzetting gaat het voortdurend over één enkele leerling/student die een toets aflegt, niet over hele klassen (proefwerken) of jaargroepen (centrale examens). Dat is een bewuste keuze. Leerlingen hebben er recht op.
Een gevolg van deze keuze is dat in het geschetste wiskundige model geen melding is gemaakt van verschillen in moeilijkheid van de vragen in de heel grote (denkbare) vragenverzameling. Moeilijkheid is immers niet gedefinieerd voor modellen voor N=1. Intrigerend? Zeker.
Het heeft alles te maken met een besliskundige benadering met de leerling als primaire beslisser, NIET de leraar. En dat hangt weer samen met de kwaliteitseis voor toetsen en examens: ze moeten door leerlingen doeltreffend zijn voor te bereiden. (De Groot 1970 https://benwilbrink.nl/publicaties/70degroot.htm )
verwijzingen met annotaties, vooral eigen publicaties op de behandelde thematiek
Francis Y. Edgeworth (1888). The statistics of examinations. Journal of the Royal Statistical Society, 51, 599-635. https://www.jstor.org/stable/2339898 [Een cruciaal inzicht was zeker in de 19e eeuw al aanwezig: een toets of examen was geen exacte meting maar behept met toevalligheden omdat het altijd maar een steekproef is. “A public examination is already a sort of lottery of the graduated species which I have been describing: one in which the chances are not equal, but are better for the more deserving; increasing with the real merit of the candidates up to a degree of probability which amounts to certainty. It is a species of sortition infinitely preferable to the ancient method of casting lots for honours and offices.“
Lee J. Cronbach & Goldine C. Gleser (1957/1965 2nd). Psychological tests and personnel decisions. University of Illinois Press. abstract: https://psycnet.apa.org/record/1965-10191-000 [Verkent test- en selectiemodellen op besliskundige leest. Met een belangrijke bijdrage van Robert van Naerssen in de 2e editie, over besliskundige selectie van chauffeurs in het Nederlandse leger, een samenvatting van zijn promotieonderzoek over dit onderwerp.]
Adriaan D. de Groot & Robert F. van Naerssen (Red.) (1969). Studietoetsen construeren, afnemen, analyseren. Mouton. (ebook inhoud/chapters alleen deel 1: https://www.degruyter.com/document/doi/10.1515/9783111559728/html ) [Dit invloedrijke standaardwerk is sterk ideologisch gekleurd. Het is van belang om daar eindelijk eens goed aandacht aan te besteden omdat hedendaagse toetspraktijken (van Cito tot uitgevers tot toetshandleidingen voor leerkrachten) de psychometrische ideologie nog steeds volgen. Beide redacteuren komen in publicaties in het erop volgende jaar tot inzichten die haaks staan op deze psychometrische mainstream. Voor een begin van een kritische analyse van het boek, zie mijn blog ‘Studietoetsen van De Groot & Van Naerssen, na 40 jaar: een beschouwing’: https://benwilbrink.nl/projecten/studietoetsen_40_jaar.htm]
A. D. de Groot (1970). Some badly needed non-statistical concepts in applied psychometrics. Nederlands Tijdschrift voor de Psychologie http://www.benwilbrink.nl/publicaties/70degroot.htm [De Groot zet de leerling/student voorop: toetsen en examens moeten door hun doeltreffend zijn voor te bereiden. Dat betekent dus ook, maar dat is mijn interpretatie, dat mainstream psychometrische benaderingen zoals in De Groot & Van Naerssen (1960) niet meer kunnen voldoen]
R. F. van Naerssen (1970). Over optimaal studeren en tentamens combineren. Openbare les. http://www.benwilbrink.nl/publicaties/70vNaerssenLes.htm [Van Naerssen paste een besliskundige benadering toe. Zoals de titel al aangeeft, plaatste ook hij de leerling/student nu voorop: wat is het voor die leerling/student om optimaal te studeren / zich doeltreffend voor te bereiden?]
Dick Tromp & Ben Wilbrink (1977). Het meten van studietijd. In: Congresboek Onderwijs Research Dagen 1977, p. 186-189. https://benwilbrink.nl/publicaties/77StudietijdORD.htm [Een toets of examen is een steekproef van wat de leerling/student op dat moment kan presteren. Het gaat niet om een stabiel kenmerk van de persoon, maar om een momentopname die afhangt van tal van omstandigheden. Het paper reduceert die ‘omstandigheden’ tot een overzichtelijk aantal: voorkennis, streefniveau, en tijdbesteding van de leerling. Deze omstandigheden zijn kwantificeerbaar, en dan is er een causaal padmodel beschikbaar dat de verbanden kwantificeert. Ik noem dit paper hier omdat we ons altijd moeten realiseren dat getoetste studieresultaten direct afhangen van factoren die we meestal NIET tegelijk vaststellen. Zonder gegevens over tijdbesteding weten we niet goed wat toetsresultaten betekenen.]
Ben Wilbrink (1978). Studiestrategieën. Examenregeling deel A. Amsterdam: COWO (docentenkursusboek 9). https://benwilbrink.nl//publicaties/78StudiestrategieCOWO.htm [Een wel heel grondige docentenkursus, uitgaande van wat voor studenten optimale stratieën zijn in de voorbereiding op tentamens. Hier komen het binomiale model voor de toets, het beta model voor de aannemelijkheid, en het betabinomiale model voor de voorspellende toetsscoreverdeling gegeven een resultaat op een proeftoets (‘mock assessment’) uitvoerig aan de orde. Omdat dit in 1978 onontgonnen terrein was, is de behandeling van deze zienswijze op toetsen nogal moeizaam, maar er volgen toch al belangrijke inzichten uit voort. Heel dit werk is geïnspireerd op de tentamenmodellen van Van Naerssen, waarvan ik eindelijk het grote belang inzag. Een deel B is er nooit gekomen (maar zie Ben Wilbrink (1979). Universitaire examenregeling): het COWO werd in de eerste grote bezuinigingsoperatie van het universitair onderwijs door het CvB-Cammelbeeck opgeheven. Dit kursusboek laat in ieder geval zien dat het betabinomiale model belangrijke toepassingen heeft. Ook al gaan docenten hier niet zelf actief mee aan de slag, zal het ze toch meer inzicht geven in wat er bij tentamens en examens speelt. Het was de bedoeling een en ander om te werken tot een (analytisch) proefschrift onder begeleiding van Wim Hofstee, maar dat is om tal van redenen niet gelukt. Het SPA-model https://benwilbrink.nl/projecten/spa_project.htm is de vrucht van alle inspanningen, maar dat strandde bijna op de eindstreep op softwareproblemen van JAVA]
Ben Wilbrink (1979). Toetsen. Amsterdam: COWO (docentenkursusboek 10). https://benwilbrink.nl/publicaties/79toetsen.cowo.htm [Hierin hoofdstuk 8. Interpretatie van toetsresultaten. Dit hoofdstuk behandelt het betabinomiaal model. De paragrafen zijn: 8.1 Beheersing van de leerstof; 8.2 Wat valt er over de toetsscore te zeggen als de ware beheersing gegeven is? {binomiaal model}; 8.3 Wat kan de student over zijn eigen ware beheersing zeggen voorafgaand aan de toets? {beta model aannemelijkheid}; 8.4 Hoe kan de student zijn toetsscore voorspellen? {betabinomiaal als voorspellende toetsscoreverdeling}; 8.5 Wat kan de docent zeggen over de ware beheersing van de student, gezien zijn toetsscore?; 8.6 Gemiddelde, standaarddeviatie, en nog enkele begrippen. {ook voor de binomiaal, beta, en betabinomiaal}; 8.7 Wegstrijken van toevalligheden in de scoreverdeling. {‘smoothing’ door een betabinomiaal te passen op de frequentieverdeling van ruwe scores voor de toets}; 8.8 Wat kan de docent zeggen over de ware beheersing van de groep studenten, gezien de testscores? {dat wordt dus een betaverdeling}; 8.9 Wat kan de docent zeggen over de ware beheersing van een enkele student, nu ook een groepssresultaat bekend is?; 8.10 Denk aan de veronderstellingen bij het gegeven model! Ik moet zeggen dat ik totaal vergeten was dat deze cursus ook dit wiskundige model behandelde. Het is allemaal wat stug, omdat er in die tijd nog met primitieve programmeerbare rekenmachientjes van Texas Instruments gewerkt moest worden. ]
Ben Wilbrink (1979). Universitaire examenregeling: conjunctief of compensatorisch. Onderwijs Research Dagen 1979, in K. D. Thio & P. Weeda (Red.), Examenproblematiek, p. 29-43. ORD bundel. Den Haag: SVO. https://benwilbrink.nl/publicaties/79ExamenregelingORD.htm [Dit is een directe toepassing van het toetsmodel op de vraag of compensatoire examenregelingen beter zijn dan conjunctieve. De student is de primaire beslisser die een goede studiestrategie wil kiezen, misschien zelfs een optimale strategie. Daar is zowel het te kiezen streefniveau als de tijdbesteding bij van belang (Tromp & Wilbrink 1977). Interessante gedachtegang, zeker ook vergeleken met latere oppervlakkige publicaties van methodologen uit psychologische hoek in Pedagogische Studiën en Science Guide]
Ben Wilbrink (1980). Kansberekeningen bij Pais’ voorontwerp van wet toelating tot numerus fixus studies in het w.o. Centrum voor Onderzoek van het Wetenschappelijk Onderwijs COWO van de UvA. https://benwilbrink.nl/publicaties/80KansberekeningenCOWO.htm [Dit is een directe toepassing van de methode van de voorspellende toetsscoreverdeling {betabinomiaalmodel} voor het berekenen van toelatingskansen van diverse subgroepen die in het Voorontwerp van wet van onderwijsminister Pais al dan niet voorrang krijgen bij de toelating tot numerus fixusstudies. De berekeningen laten zien dat na de voorrang voor deze subgroepen er voor ‘gewone’ mannelijke eindexamenkandidaten veel te kleine toelatingskansen overblijven. Pais heet geen wetsontwerp ingediend; of mijn berekeningen daar een rol bij hebben gespeeld weet ik niet.]
Ben Wilbrink (1983). Toetsvragen schrijven. Utrecht: Het Spectrum, Aula 809. Tekst van originele versie in zijn geheel: https://benwilbrink.nl/publicaties/83ToetsvragenAula.pdf, ook integraal beschikbaar via books.google. Met deels herziene hoofdstukken, onder de titel ‘Toetsvragen ontwerpen’: https://benwilbrink.nl/projecten/toetsvragen.1.htm [In toetsland is een dominant idee dat je voor het ontwerpen van toetsvragen in de wieg gelegd moet zijn, een creatieve geest moet hebben. Maar wie de kwaliteitseis van De Groot (1970) serieus neem dat toetsen doeltreffend moeten zijn voor te bereiden, ziet in dat je leerlingen niet met creatief ontworpen toetsvragen moet belasten. Hoe dan wel? Dit boek geeft heuristieken die afgeleid zijn van een strak theoretisch kader voor het ontwerpen van toetsvragen. Overigens was dit boek dus ook bedoeld om docenten handreikingen te doen voor het zelf ontwerpen van toetsen. Achtergrond daarvan was ook dat de Universiteit van Amsterdam destijds het gangbare geheimhouden van tentamenvragen verbood omdat dat ongewenste praktijken en dus ongelijke kansen uitlokte (handeltjes in uitgelekte tentamenvragen)]
Ben Wilbrink (1986). Toetsen en testen in het onderwijs. In S.V.O. Jaarverslag/Jaarboek 1985, 275-288. Den Haag: Stichting voor Onderwijsonderzoek, https://benwilbrink.nl/publicaties/86ToetsenEnTestenSVO.htm [Wezenlijk verschil tussen testen en toetsen is dat voor het eerste de veronderstelling is dat er geen gerichte voorbereiding op is geweest, terwijl voor toetsen in het onderwijs het er juist om gaat dat leerlingen er wèl gericht op zijn voorbereid. Dat verschil heeft enrme consequenties voor wat een goede methodologie is voor bijvoorbeeld de duiding van uitkomsten. Bij tests is dat de ‘mainstream’ psychometrie, en terecht. Maar diezelfde psychometrie is juist NIET passend bij toetsen in onderwijs. Tenzij vergelijkende selectie het doel van toetsen is, dan betreden we een soort schemergebied. In bijna 100% van publicaties die het toetsen in onderwijs betreffen behandelen auteurs de toetsen alsof het psychologische tests zijn waar leerlingen zich niet inhoudelijk op hebben voorbereid. Dit artikel in het S.V.O.-jaarverslag heeft kortdurend impact gehad op de NIP (1988) Richtlijnen voor ontwikkeling en gebruik van psychologische tests en studietoetsen. Amsterdam: Nederlands Instituut voor Psychologen (Commissie voor Testaangelegenheden, Cotan). Het gaat om hoofdstuk 8: Toetsen. De Cotan heeft geen nieuwe edities van deze Richtlijnen uitgebracht, maar volgt nu de Amerikaans Standards https://www.aera.net/Newsroom/AERA-APA-and-NCME-Announce-the-Open-Access-Release-of-Standards-for-Educational-and-Psychological-Testing die internationaal gezien worden als te volgen richtlijnen. Die Standards maken helaas GEEN onderscheid tussen tests en toetsen zoals in mijn artikel beschreven. Rekening houden met hoe leerlingen/studenten zich voorbereiden is juist de kern van de besproken publicaties van De Groot (1970) en Van Naerssen (1970). Modellen die langs deze lijn zijn ontwikkeld vormen een didakometrie, door Bob Van Naerssen sterk bepleit.]
Ben Wilbrink (1987) Zelf-evaluatie voor propedeusestudenten. In Grave, W. S. de, en Nuy, H. J. P. (Red.). Leren studeren in het hoger onderwijs (p. 157-166). Almere: Versluys Uitgeverij. https://benwilbrink.nl/publicaties/87ZelfevaluatieLDS.htm [Sociale vergelijking, een wel heel andere manier om naar eigen cijfers en die van anderen te kijken. Een project in het kader van de schriftelijke raad (artikel 24 bis wet tweefasenstructuur). De resultaten van de voorgaande jaargroep studenten zijn telkens gebruikt om aankomende studenten voor te lichten over de voorspelbaarheid van eigen cijfers en dat eigen tijdbesteding daarop van invloed is {doe je best, jongelui}. Voorspelbaarheid: streefniveau/verwachting vergeleken met behaalde cijfers, terwijl ook bestede tijd aan voorbereiding is gevraagd bij ieder tentamen. Propedeuses tandheelkunde en rechten aan de UvA, in de 80er jaren. Het project leverde, zoals u kunt vermoeden, een interessante dataset op, waar verdere analyses op zijn gedaan.]
Ben Wilbrink (1992) Modelling the connection between individual behaviour and macro-level outputs. In Tj. Plomp, J. M. Pieters & A. Feteris (Eds.), European Conference on Educational Research (pp. pp. 701-704.). Enschede: University of Twente. https://benwilbrink.nl/publicaties/92ColemanModelingECER.htm [Voor het met cijfers waarderen van prestaties bestaan geen absolute normen. Nu zou je denken dat het helemaal aan docenten is om die cijfers te bepalen, maar dat is dus niet zo. En wel hierom: studenten kunnen een tegenmacht vormen door minder of juist meer te investeren in de voorbereiding op tentamens. In de ‘social systems’ theorie van James Coleman (1990, Foundations of social theory) geeft hij een wiskundig model voor dat touwtrekken tussen studenten en docenten. Docenten hebben cijfers als inzet, maar studenten hebben hun investering van tijd als inzet. Is deze impliciete onderhandeling tussen beide partijen een realistisch model? Het gerapporteerde onderzoek laat zien dat dat inderdaad het geval lijkt te zijn {voor wie dit wat zegt: de MTMM matrix heeft hoge validiteiten in de diagonaal}. Dit fenomeen kan dus ook een hypothetische verklaring zijn voor verschijnselen zoals de ‘wetmatigheid van Posthumus (1940 https://www.dbnl.org/tekst/_gid001194001_01/_gid001194001_01_0040.php)’, de vrijwel constante percentages zittenblijvers in de HBS tot aan WOII. De variabelen in dit spel: voorkennis, streefniveaus/verwachtingen en tijdbesteding, versus behaalde cijfers. Data: studenten in de propedeuse rechten, 80er jaren. Zie Tromp & Wilbrink (1977) voor een eenvoudig padmodel voor deze variabelen. Het Coleman-model gaat een belangrijke stap verder: het is een dynamisch model. Zie ook onderaan de webpagina de korte briefwisseling met James Coleman. Het is een gemiste kans dat dit onderzoek niet verder is gepubliceerd, de stress in de 90er-jaren maakte dat wel heel lastig.]
1995
1995
Ben Wilbrink (1998). Inzicht doorzichtig toetsen. In Theo H. Joostens en Gerard W. H. Heijnen (Red.). Beoordelen, toetsen en studeergedrag. Groningen: Rijksuniversiteit, GION – Afdeling COWOG Centrum voor Onderzoek en Ontwikkeling van Hoger Onderwijs, 13-29. https://benwilbrink.nl/publicaties/98InzichtToetsenCOWOG.htm [Deze bijdrage aan het lustrum-seminar van het COWOG laat een wel heel interessante toepassing van het toetsmodel zien. Mij werd gevraagd of ik een paper kon indienen over het toetsen van inzicht. Ik had een handig toetsmodel, hoe zou ik dat kunnen inzetten? In dat toetsmodel is de belangrijkste parameter de ware beheersing ‘p’. Bij inzicht gaat het om complexere vragen dan gewoon kennis. Het idee is dan {mijn inzicht hè!} om die parameter ‘p’ op te vatten als staande voor parate kennis van begrippen, eventueel ook van eenvoudige relaties, en inzicht als het tegelijkertijd ‘weten’ van alle afzonderlijke elementen {begrippen, basale relaties} die voor de oplossing van de inzichtvraag nodig zijn. Technisch: dat gelijktijdig beschikbaar hebben van kennis heet ‘spreading activation’. Voeg dan ook een eenvoudig leermodel toe voor kennis van begrippen en basale relaties. Daarmee hebben we het toetsen van inzicht tot zijn kale essentie teruggebracht, in een model waaraan gerekend of ook gesimuleerd kan worden. Al rekenend blijkt dan dat inzichtvragen al gauw veel moeilijker blijken te zijn dan men op het eerste gezicht geneigd is te denken {als bijv. vijf kenniselementen tegelijk beschikbaar moeten zijn, dan mag er dus geen enkele ontbreken: kansen zijn dan conjunctief, je moet ze met elkaar vermenigvuldigen: ‘p’ tot de macht 5}. Afijn, lees het paper. De lezing in Groningen was een succes, ik had er ook bijzonder plezier in om mijn verhaal daar te presenteren voor de Groningse collega’s. Over toets- en examenvragen die (veel) te moeilijk zijn kom ik nog te spreken naar aanleiding van een recent (2023) artikel geschreven voor Van12tot18.]
2023
